腾讯混元 UniRL:统一多模态模型强化学习的开源框架
📅 2026年06月15日 · 技术
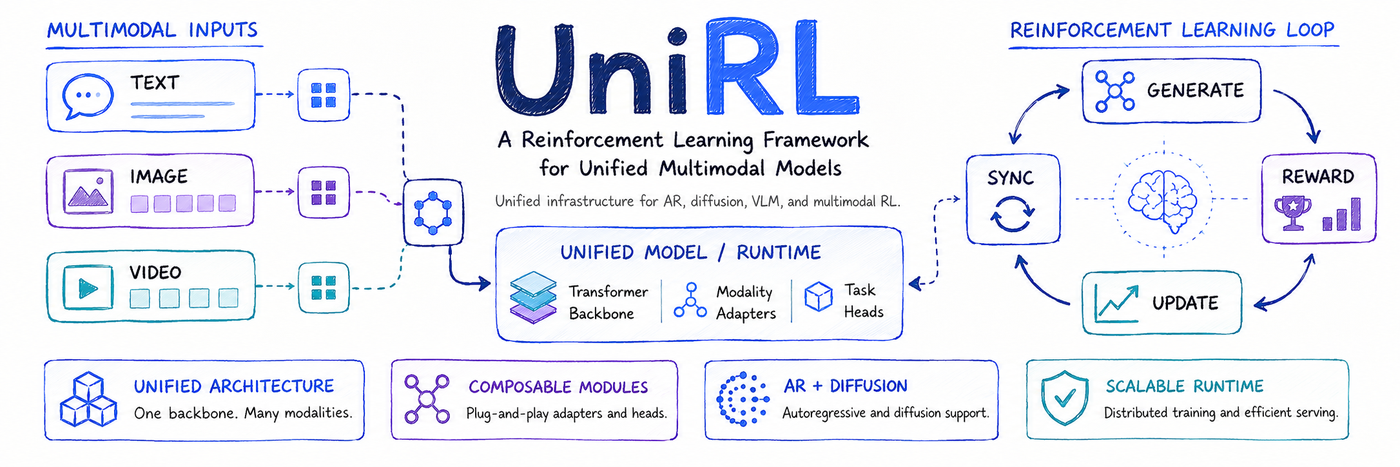
大模型预训练完之后,强化学习(RL)后训练那一轮,往往决定了它最终好不好用。但 RL 训练这件事工程门槛很高:要管 rollout 采样、奖励计算、优势估计、策略更新,还要把新权重同步回一堆 rollout worker。如果再叠上"多模态"——既要训自回归(AR)文本模型,又要训扩散(Diffusion)图像 / 视频模型,那每套范式都得从头搭一遍。腾讯混元团队开源的 UniRL,目标就是用"一套训练循环"覆盖多个多模态模型家族。
一套循环,覆盖多种范式
UniRL 把 RL 后训练抽象成一个统一的循环:生成样本 → 打分 → 算优势 → 更新策略 → 把权重同步回 rollout worker。这个循环被做成可插拔的:不同的 rollout engine、algorithm、model bundle、reward service 都能组合替换。框架提供了几个入口(entrypoint),分别对应:
train_diffusion— 扩散模型 RLtrain_ar— 自回归(文本)模型 RLtrain_pe— 参数高效微调(PE)train_unified_model— 统一多模态模型
每个入口背后挂载一个对应的 trainer(如 DiffusionTrainer、ARTrainer、UnifiedModelTrainer),通过 Hydra config 统一管理模型、算法、rollout、奖励、放置与同步策略。
团队自研算法是亮点
UniRL 把混元团队自己提出的几个算法作为亮点放了出来,每个都配了 step-by-step 教程和可跑的 recipe:
- DRPO — 重新思考 LLM RL 中的散度正则。
- Flow-DPPO — 面向 Flow Matching 模型的散度近端策略优化。
- CPPO — 超越 LLM RL 里"均匀 token 级信任域"的思路。
分布式运行时
底层依赖 Ray 的 DevicePool、FSDP、Transfer Queue,支持 LoRA 与全权重两种同步模式。整套系统是分层组合式的,想替换某一块(比如换个 rollout 引擎或奖励服务)而无需动其他部分。
适合谁
如果你正在做多模态模型的 RL 后训练,又不想为扩散和自回归各搭一套 pipeline,UniRL(Apache 2.0、Python 3.12+)提供了一个统一、可复用的起点。配套文档站和微信群都在 README 里。